|
Kaisiyuan Wang
I am currently a research scientist of Baidu VIS. I received my B.S. & M.S. degree from Harbin Institute of Technology, Electrical and Engineering School and Ph.D. degree from the University of Sydney, Electrical and Information Engineering School.
Since 2022, I have been a research intern at Department of Computer Vision Technology (VIS), Baidu Inc, working closely with Hang Zhou and Ziwei Liu on both audio/video-driven high-fidelity and efficient human video synthesis techniques. Previously, I also had a pleasant intern experience in Mobile Intelligence Group (MIG), Sensetime working with Wayne Wu, Qianyi Wu and Xinya Ji on Emotional Talking Face Generation.
Email /
CV /
Google Scholar /
Github
|

|
|
Research
My research interests include both human-centric (e.g., Human Video Synthesis and Co-speech Gesture Generation) and object-centric (e.g., Object-Compositional Implicit Scene Reconstruction) topics. Recently, I am pushing research in Human-Object Interaction (HOI) that can be applied in practical video generation techniques under digital human scenarios.
|
|
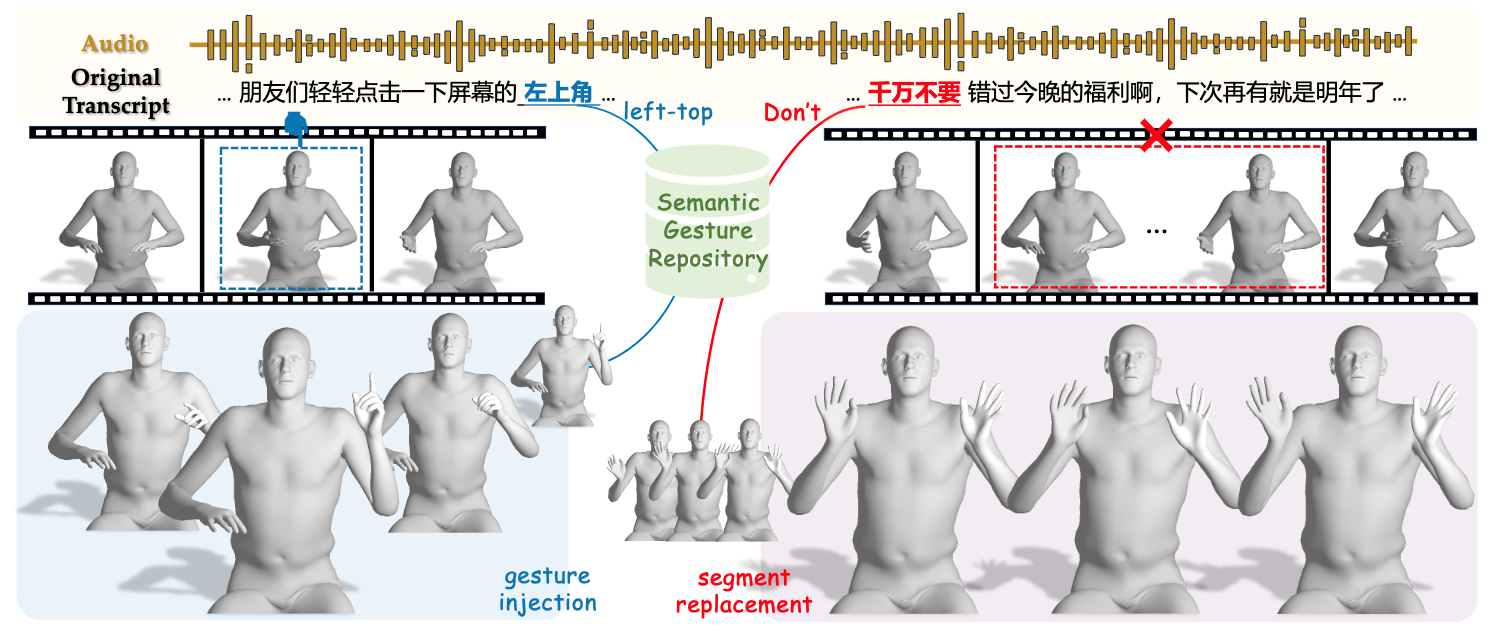
GestureHYDRA: Semantic Co-speech Gesture Synthesis via Hybrid Modality Diffusion Transformer and Cascaded Synchronized Retrieval-Augmented Generation
Quanwei Yang,
Luying Huang,
Kaisiyuan Wang†,
Jiazhi Guan,
Shengyi He,
Fengguo Li,
Lingyun Yu,
Yingying Li,
Haocheng Feng,
Hang Zhou,
Hongtao Xie†
ICCV2025
project page
/
pdf
/
code
|
|
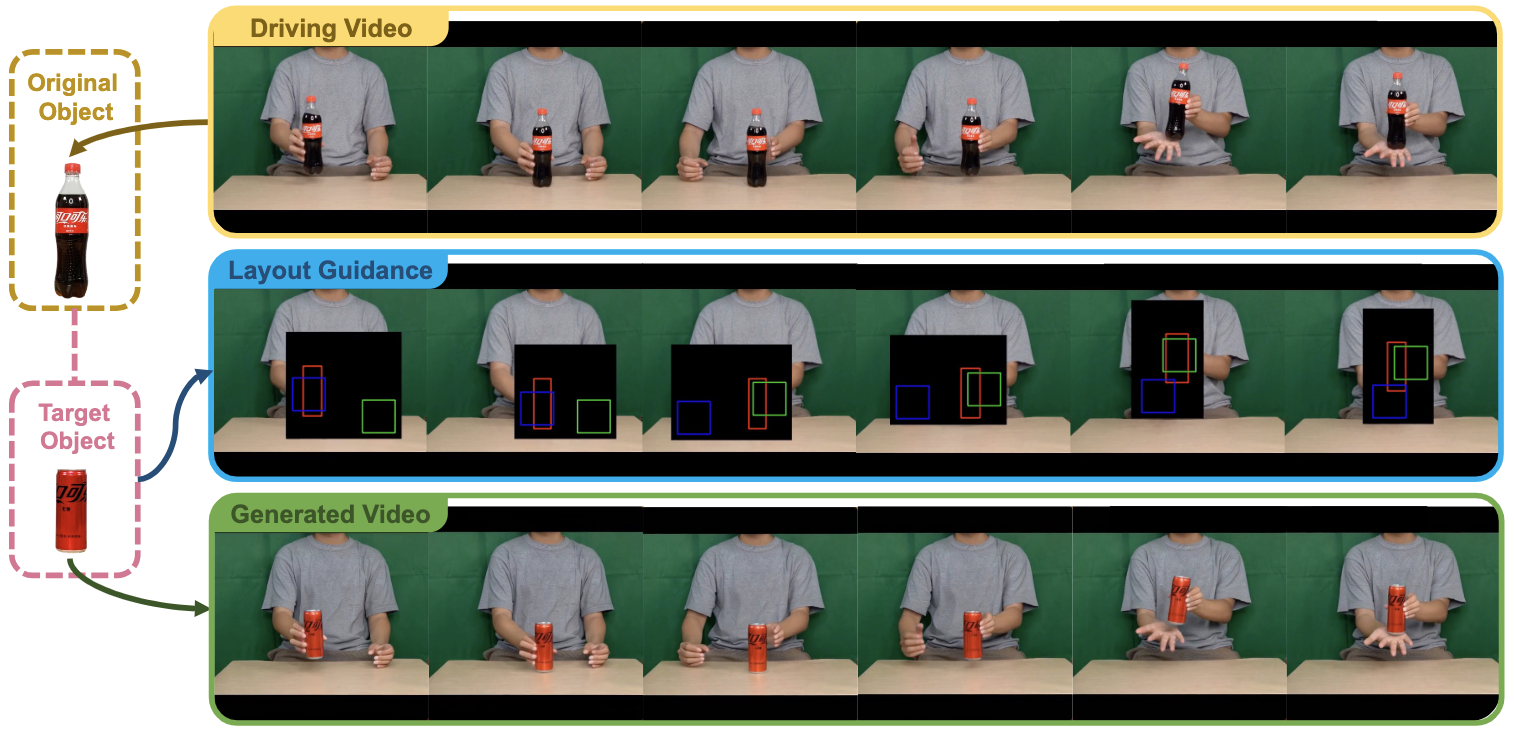
Re-HOLD: Video Hand Object Interaction Reenactment via adaptive Layout-instructed Diffusion Model
Yingying Fan,
Quanwei Yang,
Kaisiyuan Wang†,
Hang Zhou,
Yingying Li,
Haocheng Feng,
Errui Ding,
Yu Wu†,
Jingdong Wang
CVPR2025
project page
/
pdf
/
code
|

|
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Jiazhi Guan,
Kaisiyuan Wang,
Zhiliang Xu,
Quanwei Yang,
Yasheng Sun,
Shengyi He,
Borong Liang,
Yingying Li,
Haocheng Feng,
Errui Ding,
Jingdong Wang,
Youjian Zhao†,
Hang Zhou†,
Ziwei Liu
CVPR2025
project page
/
pdf
/
code
|
|
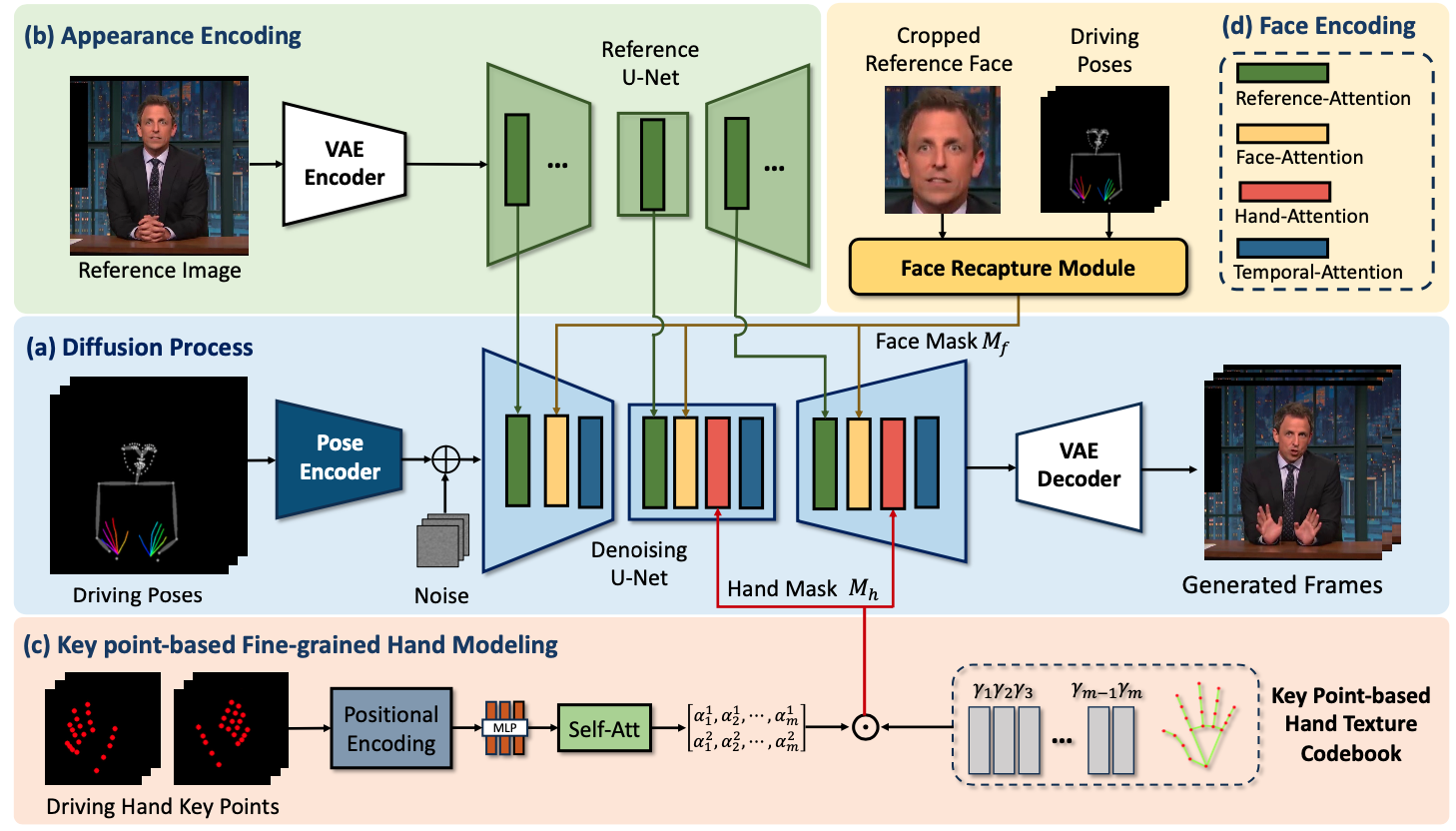
ShowMaker: Creating High-Fidelity 2D Human Video via Fine-Grained Diffusion Modeling
Quanwei Yang,
Jiazhi Guan,
Kaisiyuan Wang†,
Lingyun Yu,
Wenqing Chu,
Hang Zhou,
Errui Ding,
Jingdong Wang,
Hongtao Xie†
NeurlPS2024
project page
/
pdf
/
code
|

|
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Jiazhi Guan,
Quanwei Yang,
Kaisiyuan Wang,
Hang Zhou,
Shengyi He,
Zhiliang Xu,
Haocheng Feng,
Errui Ding,
Jingdong Wang,
Hongtao Xie,
Youjian Zhao,
Ziwei Liu
Siggraph Asia2024
project page
/
pdf
/
code
|

|
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Jiazhi Guan,
Zhiliang Xu,
Hang Zhou,
Kaisiyuan Wang,
Shengyi He,
Zhanwang Zhang,
Borong Liang,
Haocheng Feng,
Errui Ding,
Jingtuo Liu,
Jingdong Wang,
Youjian Zhao,
Ziwei Liu
ECCV2024
project page
/
pdf
/
code
|
|
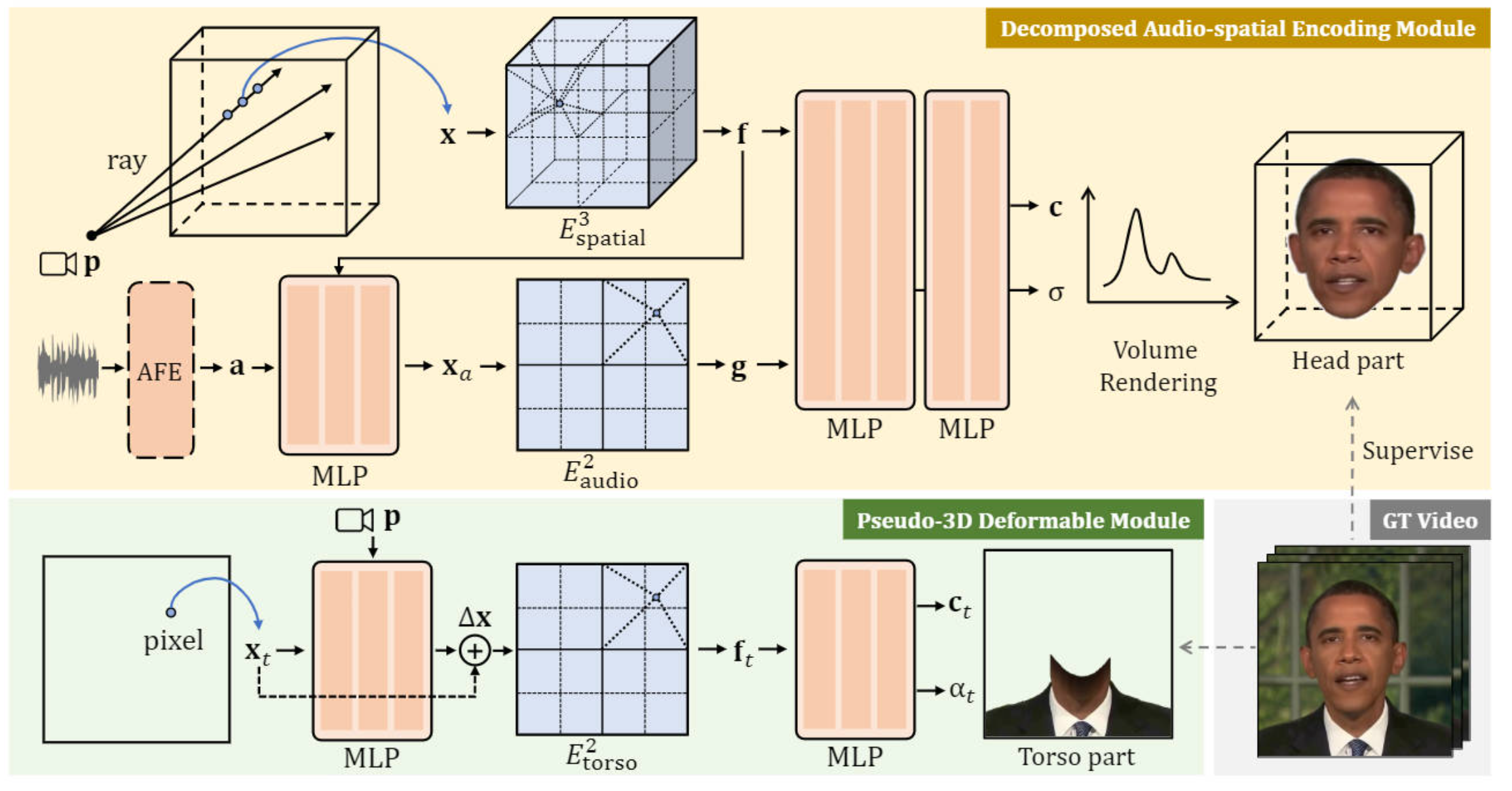
Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
Jiaxiang Tang,
Kaisiyuan Wang,
Hang Zhou,
Xiaokang Chen,
Dongliang He,
Tianshu Hu,
Jingtuo Liu,
Gang Zeng,
Jingdong Wang
Arxiv
project page
/
pdf
/
code
|
|
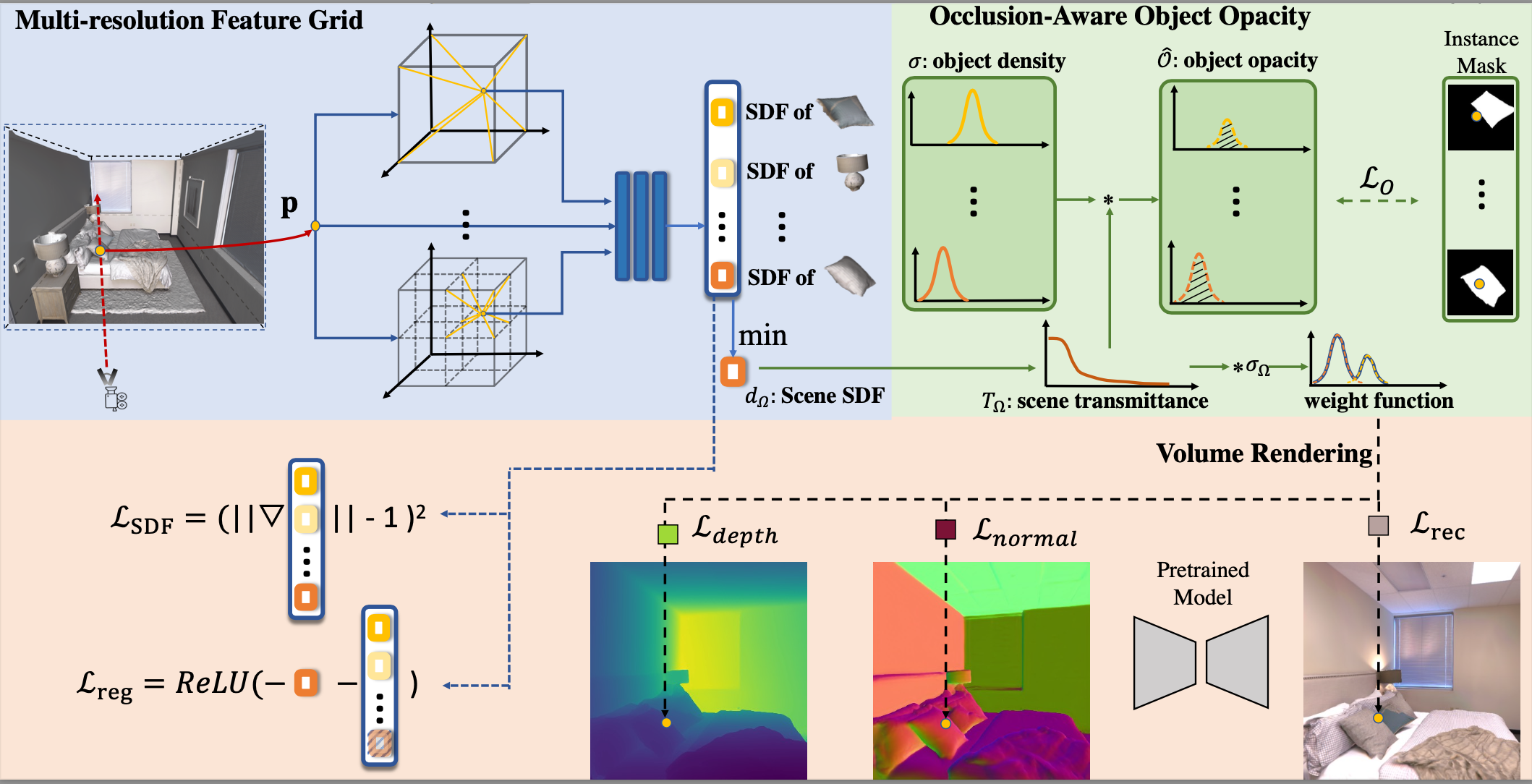
Objectsdf++: Improved Object-Compositional Neural Implicit Surfaces
Qianyi Wu,
Kaisiyuan Wang,
Kejie Li
Jianmin Zheng
Jianfei Cai
ICCV, 2023
project page
/
pdf
/
code
|

|
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
Jiazhi Guan,
Zhanwang Zhang,
Hang Zhou,
Tianshu Hu,
Kaisiyuan Wang,
Dongliang He,
Haocheng Feng,
Jingtuo Liu,
Errui Ding,
Ziwei Liu,
Jingdong Wang
CVPR, 2023
project page
/
pdf
/
code
|
|
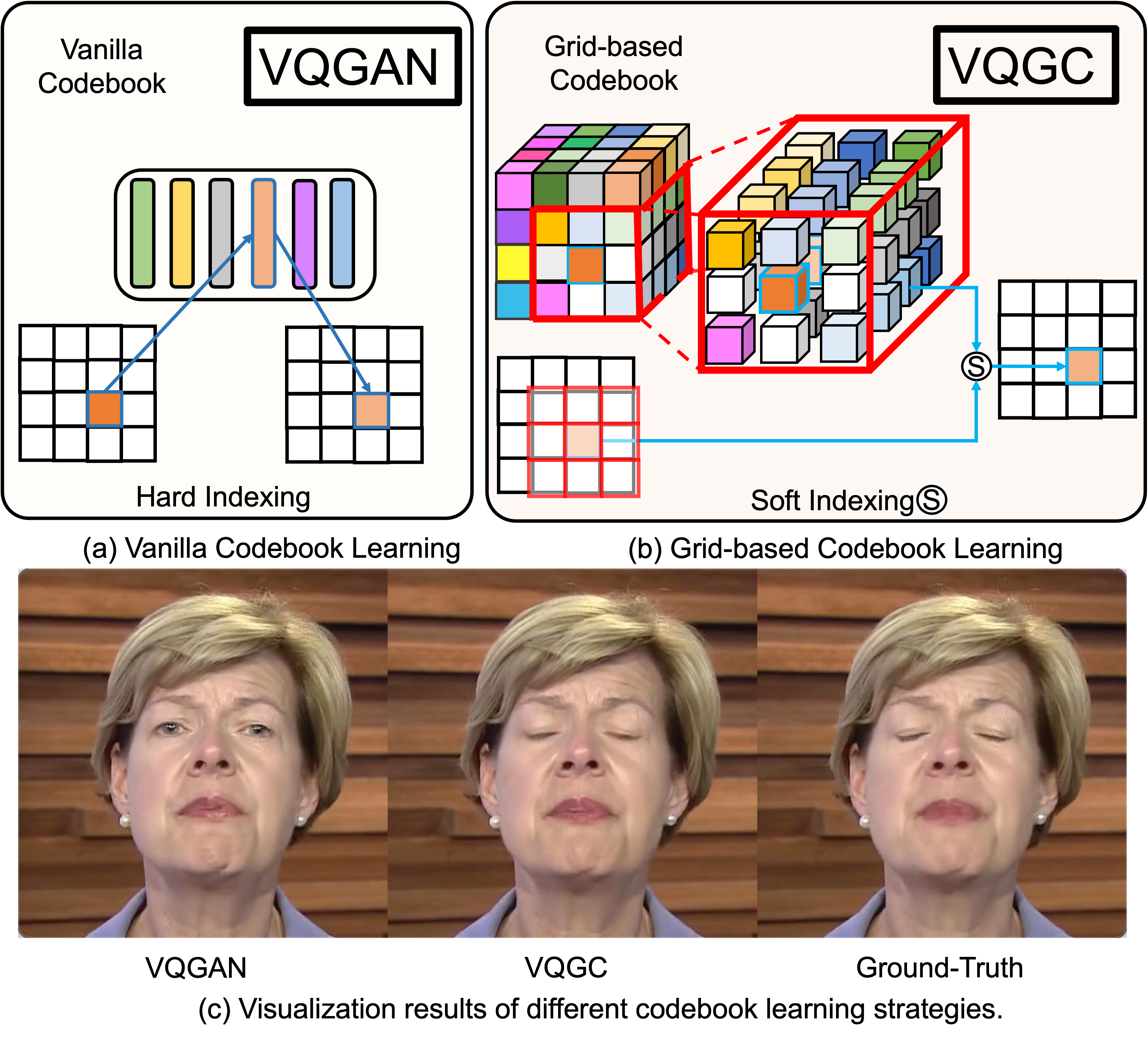
Efficient Video Portrait Reenactment via Grid-based Codebook
Kaisiyuan Wang,
Hang Zhou,
Qianyi Wu,
Jiaxiang Tang,
Tianshu Hu,
Zhiliang Xu,
Borong Liang,
Tianshu Hu,
Errui Ding,
Jingtuo Liu,
Ziwei Liu,
Jingdong Wang
Siggraph, 2023
project page
/
pdf
/
code
|
|
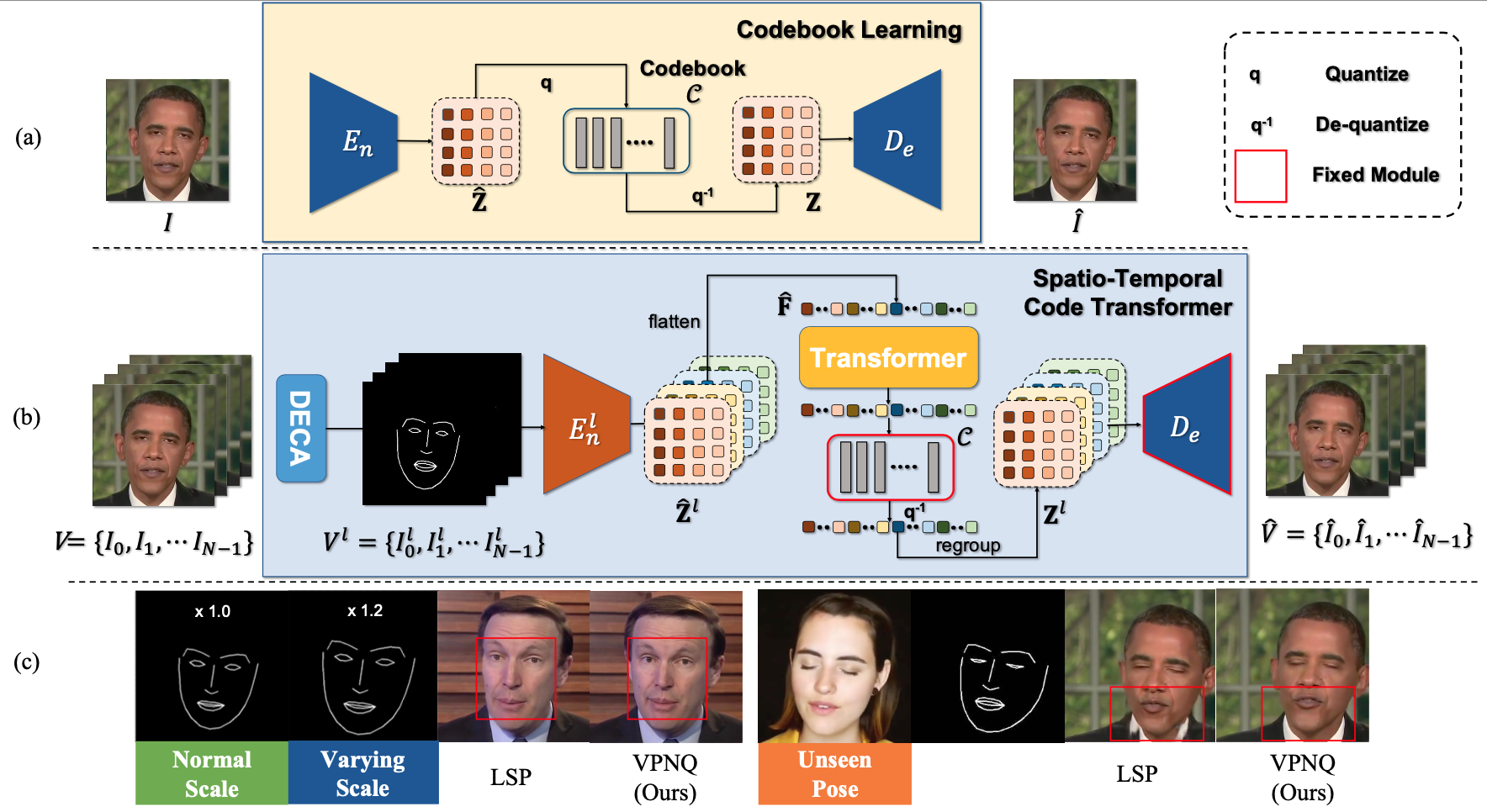
Robust Video Portrait Reenactment via Personalized Representation Quantization
Kaisiyuan Wang,
Changcheng Liang,
Hang Zhou,
Jiaxiang Tang,
Qianyi Wu,
Dongliang He,
Zhibin Hong,
Jingtuo Liu,
Errui Ding,
Ziwei Liu,
Jingdong Wang
AAAI, 2023
project page
/
pdf
/
code
|
|
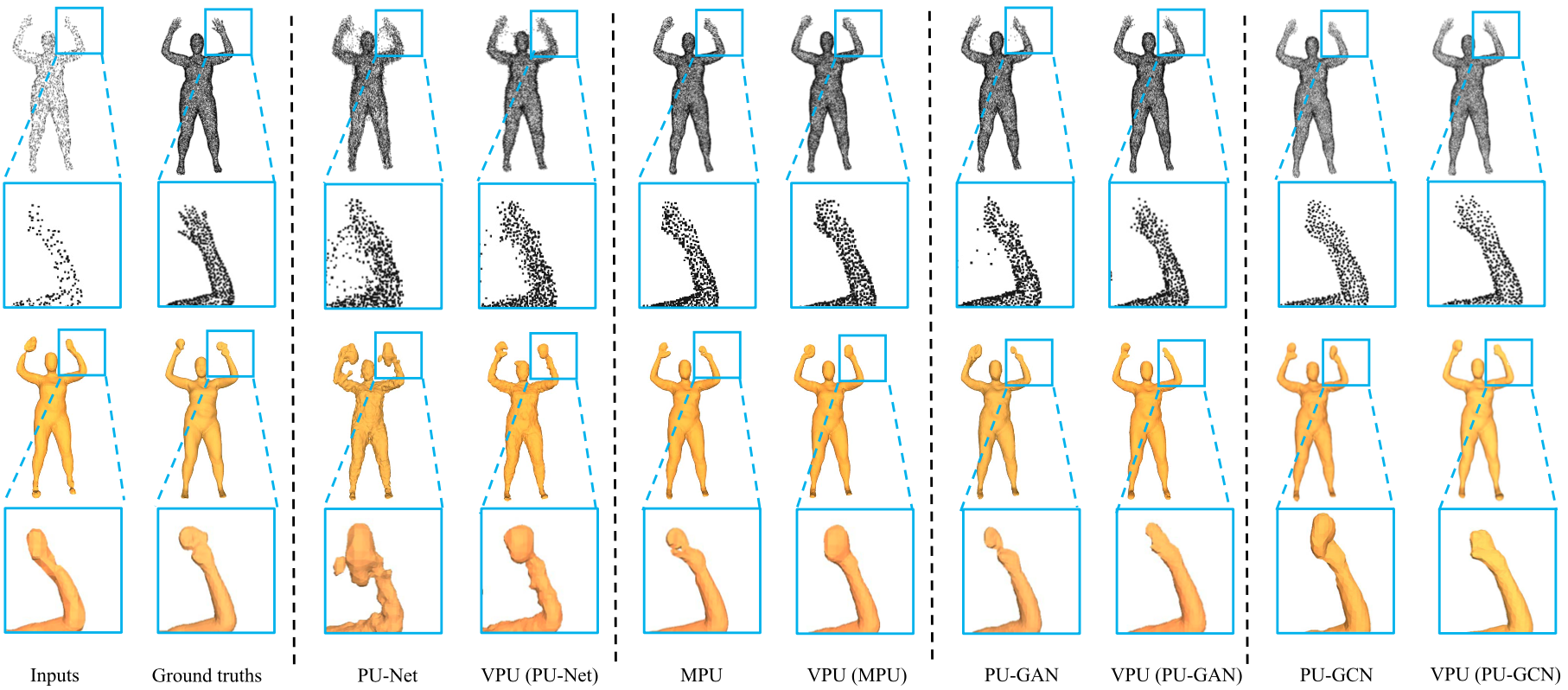
VPU: A Video-based Point cloud Upsampling framework
Kaisiyuan Wang,
Lu Sheng,
Shuhang Gu,
Dong Xu,
TIP, 2022
project page
/
pdf
/
code
|
|
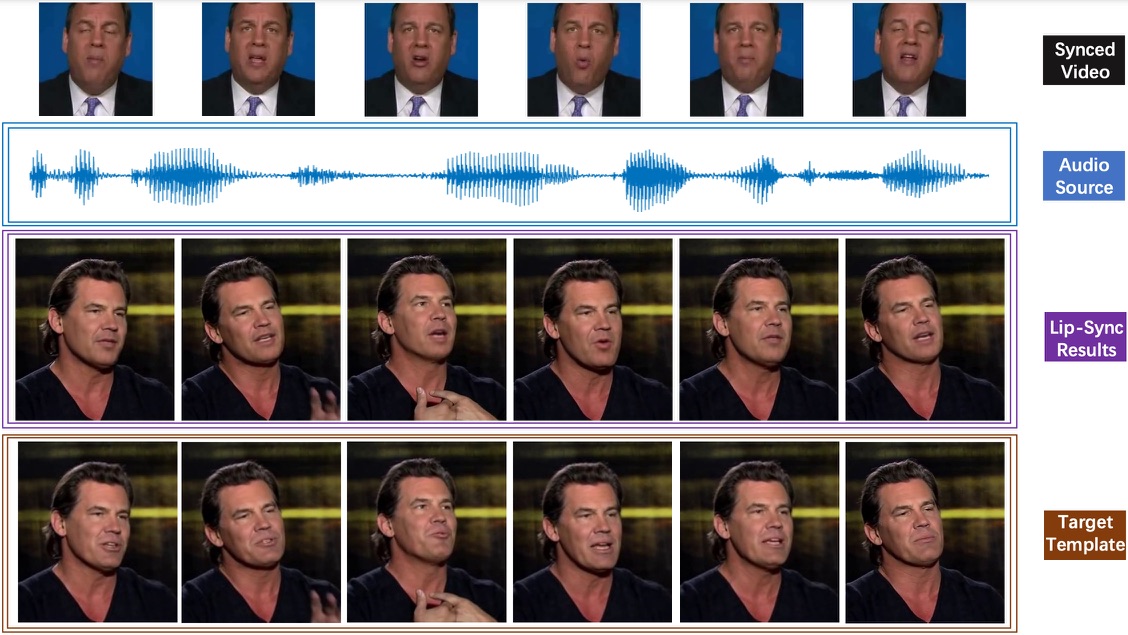
Masked lip-sync prediction by audio-visual contextual exploitation in transformers
Yasheng Sun*,
Hang Zhou*,
Kaisiyuan Wang,
Qianyi Wu,
Zhibin Hong,
Jingtuo Liu,
Errui Ding,
Jingdong Wang,
Ziwei Liu,
Koike Hideki
Siggraph Asia, 2022
project page
/
pdf
/
code
|

|
EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model
Xinya Ji,
Hang Zhou,
Kaisiyuan Wang,
Qianyi Wu,
Wayne Wu,
Feng Xu,
Xun Cao
Siggraph, 2022
project page
/
pdf
/
code
|

|
Audio-Driven Emotional Video Portraits
Xinya Ji,
Hang Zhou,
Kaisiyuan Wang,
Qianyi Wu,
Wayne Wu,
Chen Change Loy,
Xun Cao,
Feng Xu
CVPR, 2021
project page
/
pdf
/
code
|

|
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation
Kaisiyuan Wang,
Qianyi Wu,
Linsen Song,
Zhuoqian Yang,
Wayne Wu,
Chen Qian,
Ran He,
Yu Qiao,
Chen Change Loy,
ECCV, 2020
project page
/
pdf
/
code
|

|
Research Intern for Digital Human
| VIS, Baidu Inc.
Beijing, China | Feb. 2022 ~ Now
-
Personalized Video Portrait Reenactment
-
Person-agnostic Audio-driven Talking Head Synthesis
|

|
Research Intern for Digital Human
| MIG, Sensetime
Beijing, China | Apr. 2019 ~ Jun. 2020
-
2D/3D Emotional Facial Expression Generation
-
Audio-driven Emotional Talking Head Synthesis
|
This website is adapted from Jon Barron's template.
|
|